Dec 18, 2025 - 12 min
Why MAP and MRR are not a good choice for Search Ranking
Search ranking practitioners often use Mean Reciprocal Rank (MRR) and Mean Average Precision (MAP) to assess the quality of their rankings. In this post, we will discuss why MAP and MRR are bad for search ranking. We then look at two metrics that serve as better alternatives to MRR and MAP.
What are MRR and MAP?
Mean Reciprocal Rank (MRR)
Mean Reciprocal Rank (MRR) is the average rank where the first relevant item occurs.
In e-commerce, the first relevant rank can be the rank of the first item clicked in response to a query
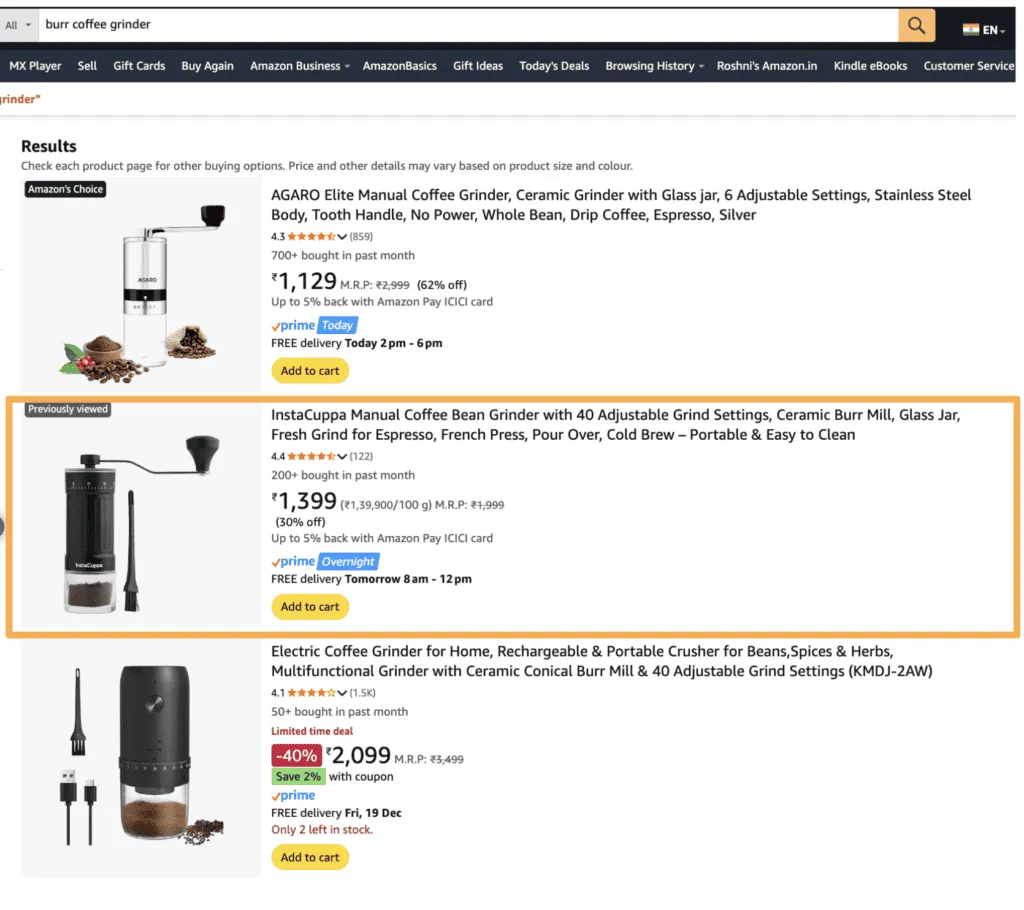
An Amazon search for ‘burr coffee grinder’. Here, we assume the second item is the relevant result.
For the above example, assume the relevant item is the second item. This means
Reciprocal rank is calculated for all the queries in the evaluation set. To get a single metric for all the queries, we take the mean of reciprocal ranks to get the Mean Reciprocal Rank
where
Mean Average Precision (MAP)
Mean Average Precision (MAP) measures how well the system retrieves relevant items and how early they are shown. We begin by first calculating Average Precision (AP) for each query. We define AP as
where
is the number of relevant items for the query is the average of across queries
The above equation looks a lot, but it is actually simple. Let’s use an example to break it down. Assume a query has 3 relevant items, and our model predicts the following order
Rank: 1 2 3 4 5
Item: R N R N R(R = relevant, N = not relevant)
To compute the MAP, we compute the AP at each relevant position:
- @1: Precision = 1/1 = 1.0
- @3: Precision = 2/3 ≈ 0.667
- @5: Precision = 3/5 = 0.6
We calculate the above for all the queries and average them to get the MAP. The AP formula has two important components
- Precision@k: Since we use Precision, retrieving relevant items earlier yields higher precision values. If the model ranks relevant items later, Precision@k reduces due to a larger k
- Averaging the Precisions: We average the precisions over the total number of relevant items. If the system never retrieves an item or retrieves it beyond the cutoff, the item contributes nothing to the numerator while still counting in the denominator, which reduces AP and MAP.
Why MAP and MRR are Bad for Search Ranking
Now that we have covered the definitions, let’s understand why MAP and MRR are not used for search results ranking.
Relevance is Graded, not Binary
When we compute MRR, we take the rank of the first relevant item. In MRR, we treat all relevant items the same. It makes no difference if a different relevant item shows up first. In reality, different items tend to have different relevance.
Similarly, in MAP, we use binary relevance- we simply look for the next relevant item. Again, MAP makes no distinction in the relevance score of the items. In real cases, relevance is graded, not binary.
Item : 1 2 3
Relevance: 3 1 0MAP and MRR both ignore how good the relevant item is. They fail to quantify the relevance.
Users Scan Multiple Results
This is more specific to MRR. In MRR computation, we record the rank of the first relevant item. And ignore everything after. It can be good for lookups, QA, etc. But this is bad for recommendations, product search, etc.
During search, users don’t stop at the first relevant result (except for cases where there is only one correct response). Users scan multiple results that contribute to overall search relevancy.
MAP overemphasizes recall
MAP computes
As a consequence, every relevant item contributes to the scoring. Missing any relevant item hurts the scoring. When users make a search, they are not interested in finding all the relevant items. They are interested in finding the best few options. MAP optimization pushes the model to learn the long tail of relevant items, even if the relevance contribution is low, and users never scroll that far. Hence, MAP overemphasizes recall.
MAP Decays Linearly
Consider the example below. We place a relevant item at three different positions and compute the AP
| Rank | Precision@k | AP |
|---|---|---|
| 1 | 1/1 = 1.0 | 1.0 |
| 3 | 1/3 ≈ 0.33 | 0.33 |
| 30 | 1/30 ≈ 0.033 | 0.033 |
AP at Rank 30 looks worse than Rank 3, which looks worse than Rank 1. The AP score decays linearly with the rank. In reality, Rank 3 vs Rank 30 is more than a 10x difference. It’s more like seen vs not seen.
MAP is position sensitive but only weakly. It doesn’t reflect how user behavior changes with position. MAP is position-sensitive through Precision@k, where the decay with rank is linear. This does not reflect how user attention drops in search results.
NDCG and ERR are Better Choices
For search results ranking, NDCG and ERR are better choices. They fix the issues that MRR and MAP suffer from.
Expected Reciprocal Rank (ERR)
Expected Reciprocal Rank (ERR) assumes a cascade user model wherein a user does the following
- Scans the list from top to bottom
- At each rank
, - With probability
, the user is satisfied and stops - With probability
, the user continues looking ahead
- With probability
ERR computes the expected reciprocal rank of this stopping position where the user is satisfied:
where
Let’s understand how ERR is different from MRR.
- ERR uses
, which is graded relevance, so a result can partially satisfy a user - ERR allows for multiple relevant items to contribute. Early high-quality items reduce the contribution of later items
Example 1
We’ll take a toy example to understand how ERR and MRR differ
Rank: 1 2 3
Relevance: 2 3 0- MRR = 1 (relevant item is at first place)
- ERR =
- MRR says perfect ranking. ERR says not perfect because a higher relevance item appears later
Example 2
Let’s take another example to see how a change in ranking impacts the ERR contribution of an item. We will place a highly relevant item at different positions in a list and compute the ERR contribution for that item. Consider the cases below
- Ranking 1:
- Ranking 2:
Lets compute
| Relevance | ||
|---|---|---|
| 4 | 15 | 0.0586 |
| 8 | 255 | 0.9961 |
Using this to compute the full ERR for both the rankings, we get:
- Ranking 1: ERR ≈ 0.99
- Ranking 2: ERR ≈ 0.27
If we specifically look at the contribution of the item with the relevance score of 8, we see that the drop in contribution of that term is 6.36x. If the penalty were linear, the drop would be 5x.
| Scenario | Contribution of relevance-8 item |
|---|---|
| Rank 1 | 0.9961 |
| Rank 5 | 0.1565 |
| Drop factor | 6.36x |
Normalized Discounted Cumulative Gain (NDCG)
Normalized Discounted Cumulative Gain (NDCG) is another great choice that is well-suited for ranking search results. NDCG is built on two main ideas
- Gain: Items with higher relevance scores are worth much more
- Discount: items appearing later are worth much less since users pay less attention to later items
NDCG combines the idea of Gain and Discount to create a score. Additionally, it also normalizes the score to allow comparison between different queries. Formally, gain and discount are defined as
where
Gain has an exponential form, which rewards higher relevance. This ensures that items with a higher relevance score contribute much more. The logarithmic discount penalizes the later ranking of relevant items. Combined and applied to the entire ranked list, we get the Discounted Cumulative Gain:
for a given ranked list
IDCG represents a perfect ranking. To normalize the
NDCG@K has the following properties
- Bounded between 0 and 1
- Comparable across queries
- 1 is a perfect ordering
Example 1: Good vs Slightly Worse Ordering
In this example, we will take two different rankings of the same list and compare their NDCG values. Assume we have items with relevance labels on a 0-3 scale.
Ranking A
Rank: 1 2 3
Relevance: 3 2 1Ranking B
Rank: 1 2 3
Relevance: 3 2 1Computing the NDCG components, we get-
| Rank | Gain | Discount | A contrib | B contrib |
|---|---|---|---|---|
| 1 | 7 | 1.00 | 7.00 | 3.00 |
| 2 | 3 | 1.58 | 1.89 | 4.42 |
| 3 | 1 | 2.00 | 0.50 | 0.50 |
- DCG(A) = 9.39
- DCG(B) = 7.92
- IDCG = 9.39
- NDCG(A) = 9.39 / 9.39 = 1.0
- NDCG(B) = 7.92 / 9.39 = 0.84
Thus, swapping a relevant item away from rank 1 causes a large drop.
NDCG: Additional Discussion
The discount that forms the denominator of the DCG computation is logarithmic in nature. It increases much slower than linearly.
Let’s see how this compares with the linear decay
| Rank | Linear | Logarithmic |
|---|---|---|
| 1 | 1.00 | 1.00 |
| 2 | 0.50 | 0.63 |
| 5 | 0.20 | 0.39 |
| 10 | 0.10 | 0.29 |
| 50 | 0.02 | 0.18 |
decays faster decays slower
Logarithmic discount penalizes later ranks less aggressively than a linear discount. The difference between rank 1 → 2 is larger, but the difference between rank 10 → 50 is small.
The log discount has a diminishing marginal reduction in penalizing later ranks due to its concave shape. This prevents NDCG from becoming a top-heavy metric where ranks 1-3 dominate the score. A linear penalty would ignore reasonable choices lower down.
A logarithmic discount also reflects the fact that user attention drops sharply at the top of the list and then flattens out instead of decreasing linearly with rank.
Conclusion
MAP and MRR are useful information retrieval metrics, but are poorly suited for modern search ranking systems. While MAP focuses on finding all the relevant documents, MRR treats a ranking problem as a single-position metric. MAP and MRR both ignore the graded relevance of items in a search and treat them as binary: relevant and not relevant.
NDCG and ERR better reflect real user behavior by accounting for multiple positions, allowing items to have non-binary scores, while giving higher importance to top positions. For search ranking systems, these position-sensitive metrics are not just a better choice- they are necessary.
Further Reading
- LambdaMART (good explanation)
- Learning To Rank (highly recommend reading this. It’s long and thorough, and also the inspiration for this article!)
If you enjoyed reading this article, you can check out more blogs here.