Mar 8, 2025 - 6 min
What is KV-Cache?
If you have been reading articles on LLMs, you would have often come across an interesting term called KV-Cache and how developers are trying to do all sorts of trickery to speed up LLMs. And that is what we are going to do today– talk about KV-Cache to understand it in detail!
Before we talk about KV-Cache, we need to talk about LLMs and attention. Let’s get cracking…
Next Token Generation in LLMs
In LLMs, when we generate a new token, we take a look at the preceding tokens as part of self-attention. Self-attention is defined as
How do LLMs compute Q, K, and V?
The calculation for
Where
And this is where developers noted that we could re-use the previous calculations to speed up the process. Let us take an example where an LLM has generated the word –
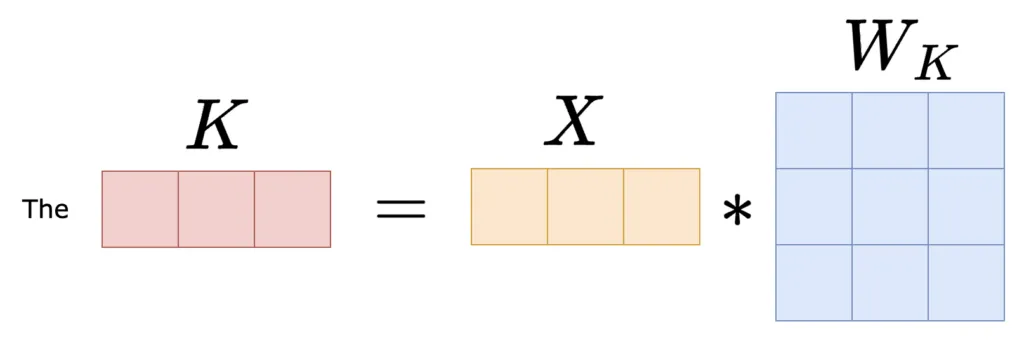
In the above image, we compute the Key (
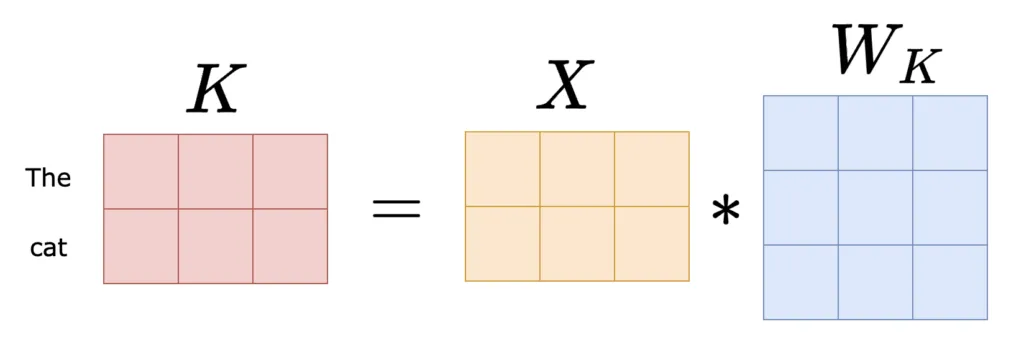
When we perform this step, we recompute the Key transformation for
How does KV-Cache Work?
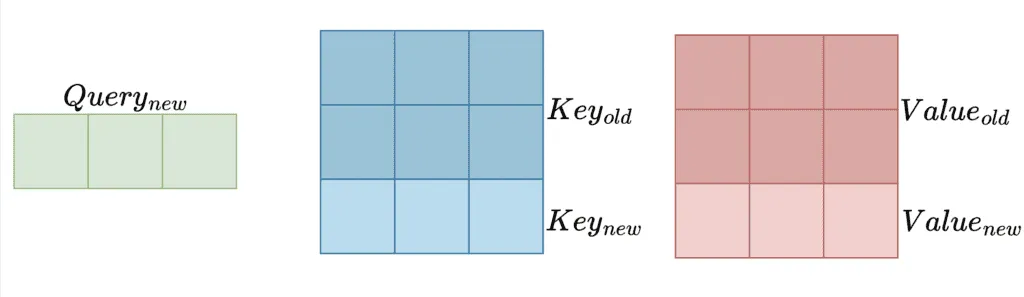
To predict the next word, LLMs rely on the preceding words. This process requires computing the
To get an intuition, think of KV-Cache as a locker room storage that allows us to retrieve the
The model caches KV data in the GPU’s VRAM to speed up inference.
It’s important to note a tradeoff. Large KV-Caches require more VRAM. If you want to use a model with a 32K+ token context size, you likely need to run it on a high-end GPU such as the NVIDIA A100 or H100, which have the necessary VRAM for KV-Cache. Consumer GPUs lack the required VRAM to store large KV-Caches. The KV-Cache size of a 32k context model can easily swell up to 48GB of VRAM (depending on the architecture of the LLM).
Why not store
Attention requires three matrices-
Well, because we don’t reuse any of the older
Conclusion and Takeaways
-
KV-Cache plays a crucial role in optimizing the efficiency of Large Language Models (LLMs) by eliminating redundant computations during token generation. By storing previously computed Key (( K )) and Value (( V )) matrices, models can significantly reduce inference latency, making real-time applications of LLMs more feasible.
-
However, this optimization comes with trade-offs—larger context windows require substantial VRAM to store KV-Cache. This is why models with 32K+ token contexts demand high-end GPUs like A100 or H100.
-
Model stores the ( K ) and ( V ) values in the KV-Cache. ( Q ) is not because the model must compute it fresh for every new token. Storing ( Q ) would provide no performance gains and would unnecessarily increase memory usage.
Further Reading
If you liked this post, you might enjoy reading my post on fine-tuning embedding models.