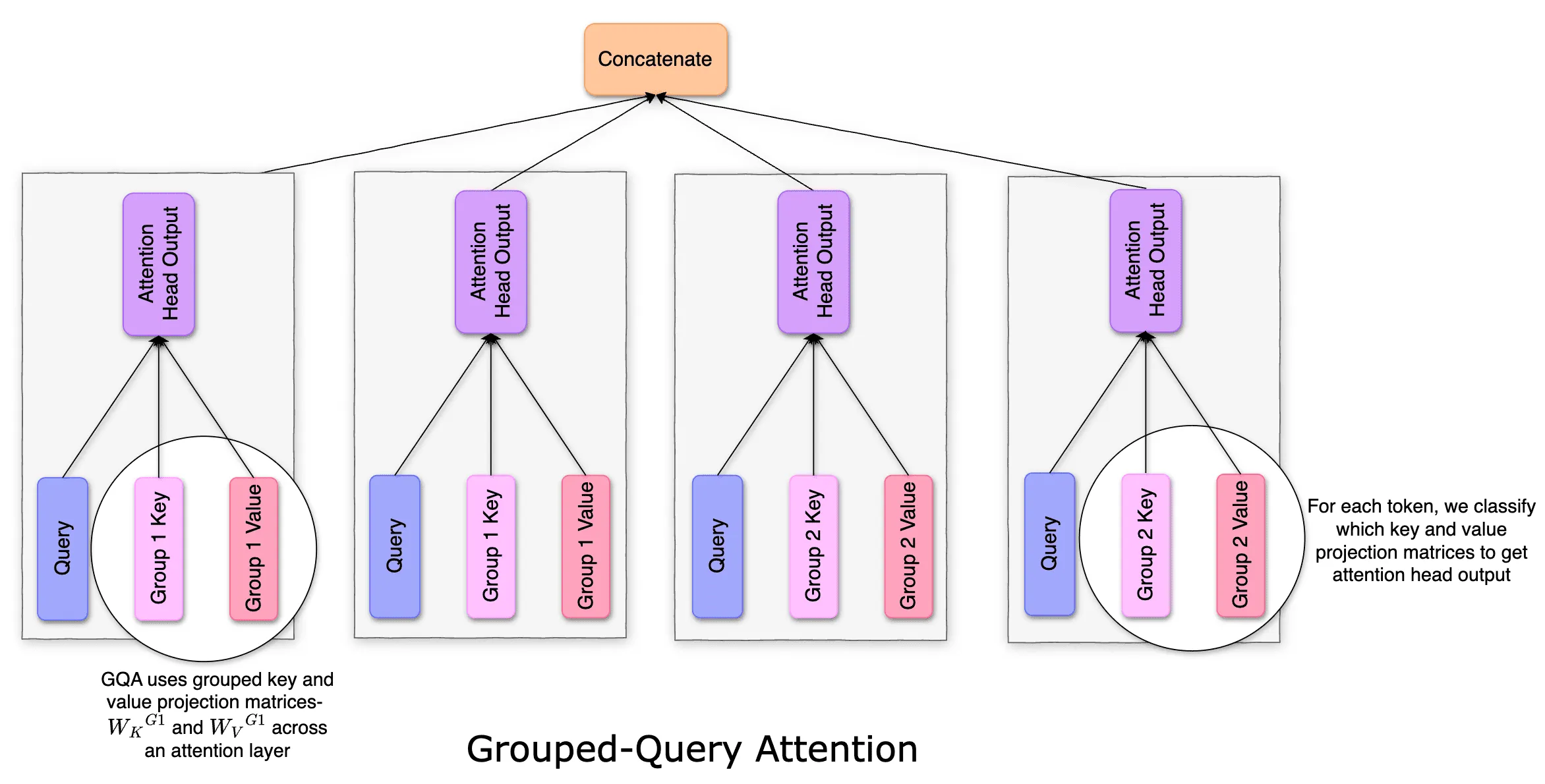
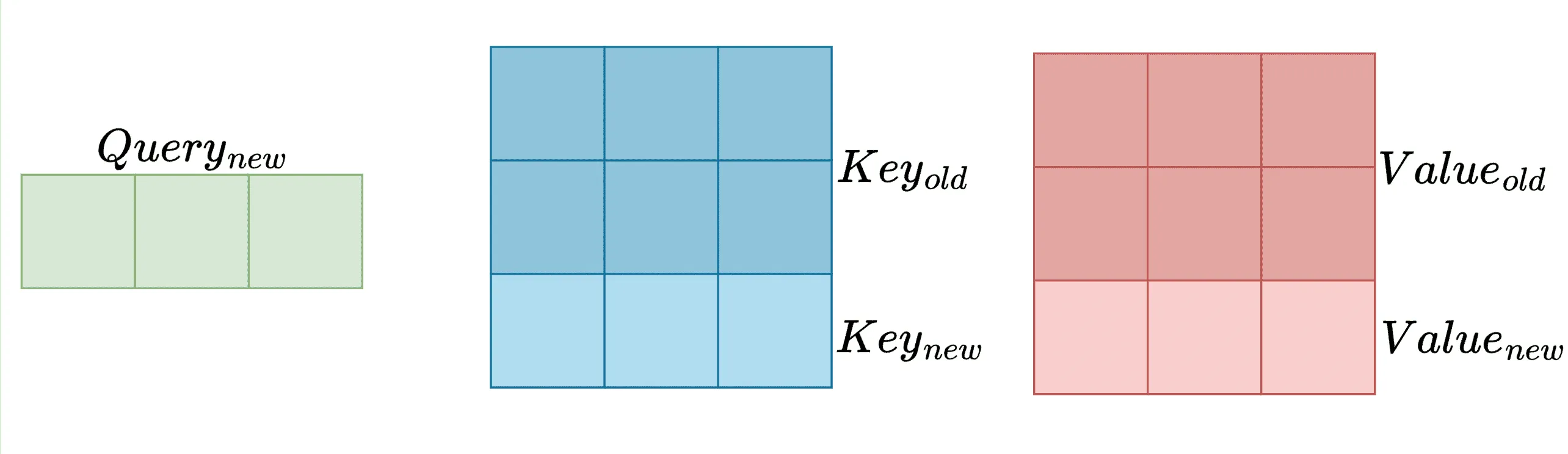
Multi-Head vs Multi-Query vs Grouped Query Attention
The title may be long, but the explanation isn't. Since the original Transformer, researchers have continuously tweaked its architecture, aiming to cut inference costs. Today, we’ll compare Multi-Head vs Multi-Query vs Grouped Query Attention to understand...